Problem
Pricing homes from messy comps
Comparative Market Analysis is the manual process real-estate agents use to price a home from recent comparable sales. It’s slow, expert-dependent, and uneven across price tiers. The goal: an ML model that estimates fair market price from objective property features (square footage, beds/baths, acreage, property type) so the human stays in the loop on judgment, not arithmetic.
Approach
Compare, blend, then audit the errors
Trained and compared five supervised models on a cleaned dataset of residential properties: Linear Regression, k-Nearest Neighbors, Random Forest, Gradient Boosting Machines (GBM), and XGBoost. Evaluated on Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) under cross-validation.
The winning model was a blend — 15% XGBoost + 85% GBM — reached via grid search over blend weights. The blend smoothed XGBoost’s aggressive splits while keeping its sensitivity to feature interactions.
Result
Good signal, with clear boundaries
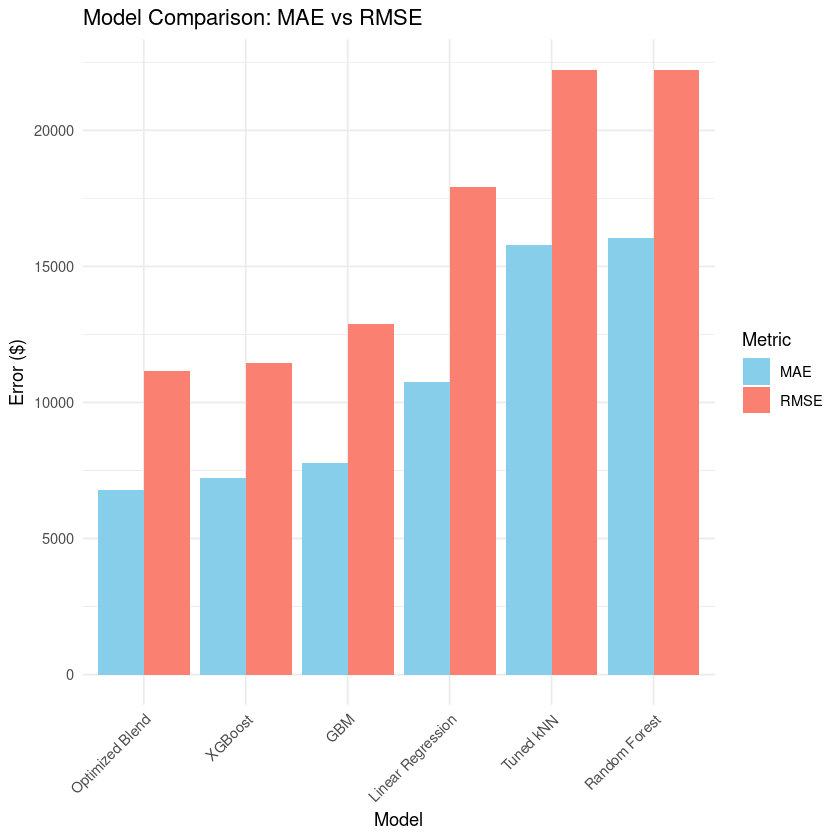
- Optimized Blend MAE: 6,776.11
- Optimized Blend RMSE: 11,166.11
- Best performance concentrated in the $130k–$185k band where comp density is highest.
Limitations
Where the model got honest
- Clustering as preprocessing hurt accuracy. Grouping by price-derived features caused class imbalance above $185k and produced erratic predictions for higher-end homes.
- Overfitting concentrated in the middle band. Strong early scores were partly an artifact of dense data in the $130k–$185k range; generalization above and below that range was weaker.
- Feature gaps mattered. Dataset lacked year built, renovation history, garages, pools, and condition grades — all of which materially move price. The model under-predicted homes with significant unmeasured upside.
Next
How I would push it further
- Source a richer dataset that includes year built, condition, and renovation history.
- Replace blanket clustering with hierarchical models per price tier.
- Add SHAP-based explanations so the agent sees why a price came out where it did.