📸 Visualizations
A machine learning approach to automate Comparative Market Analysis (CMA)
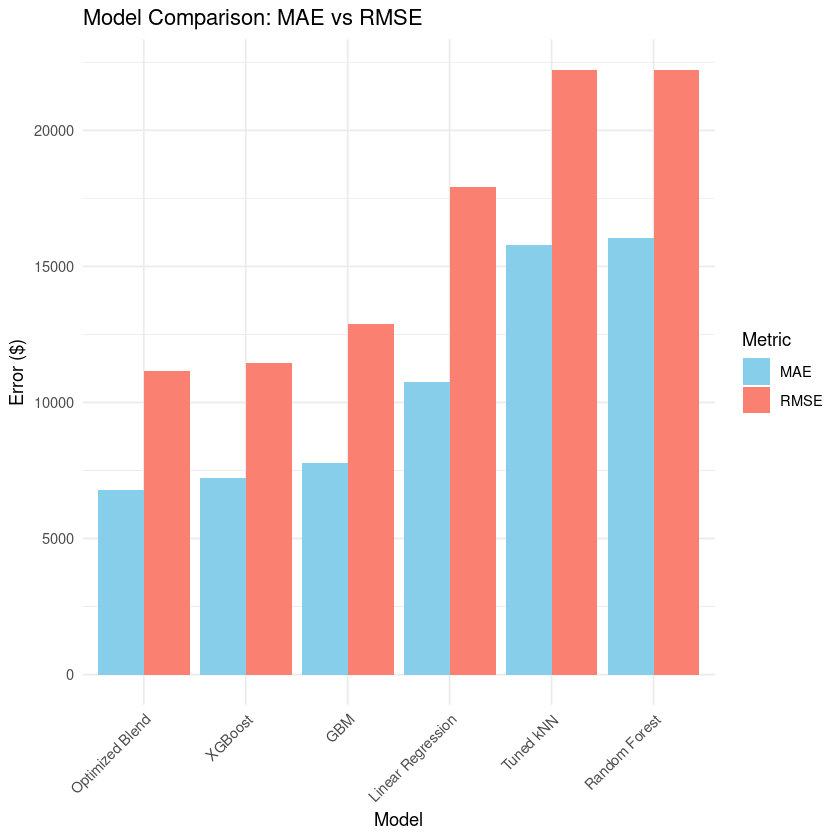
This project explores the application of machine learning (ML) for automating the Comparative Market Analysis (CMA) process in real estate valuation. Using a cleaned dataset of residential properties, we aimed to develop a predictive model that estimates the fair market price of a home based on characteristics such as square footage, number of bedrooms and bathrooms, acreage, and type of property. The goal was to provide real estate professionals, property investors, and homebuyers with a tool that can automate price prediction, removing the reliance on manual appraisals. We employed several supervised learning models, including Linear Regression, k-Nearest Neighbors (kNN), Random Forest, Gradient Boosting Machines (GBM), and XGBoost, followed by performance evaluation using Root Mean Square Error (RMSE) and Mean Absolute Error (MAE). Our best outcome came from blending the models, with an optimized blend of 15% XGBoost and 85% GBM, which achieved an Optimized Blend MAE of 6776.11 and an Optimized Blend RMSE of 11166.11. However, it’s important to note that the earlier, better results were likely due to overfitting, especially in specific price ranges. An attempt was made to apply data clustering as a preprocessing step to improve model performance. Unfortunately, this approach did not yield favorable results. Clustering caused problems, particularly in higher price ranges, where the predictions became too messy and inconsistent. The inclusion of price-derived features in the clustering led to imbalances, particularly for houses priced above $185k. Challenges and Limitations: Clustering Issues: Data clustering was initially used to group similar properties together, but it didn’t improve the model's accuracy. In the higher price ranges, clustering created erratic predictions due to a lack of sufficient data to represent these property types accurately. Overfitting: The earlier successes in model performance, especially with MAE and RMSE, were found to be a result of overfitting, particularly in the $130k to $185k price range. The model performed well within this price range but struggled to generalize for properties outside this range. Missing Features: The dataset, while comprehensive in basic real estate features (square footage, number of rooms, acreage), lacked important attributes such as year built, renovations, and additional property features like garages and pools. These gaps in data contributed to some inaccuracy in predictions, particularly for properties that had special features not captured in the dataset.